UC3 - Drosophila Genetics#
Combining earth observation and genomics data to study the evolutionary history of the fruit fly Drosophila melanogaster.
In our “Drosophila genomics” use case, we take advantage of comprehensive earth observation data for climate and land use available in the public domain.
We will combine environmental data with genomic information of fruit fly DNA samples from Drosophila melanogaster populations and explore how environments shape the ecology and evolution of the species. Taking Vienna as a specific example for urban habitats — with its mix of dense cityscapes, green spaces, and suburban habitats — we specifically want to investigate the composition of local Drosophila communities, the genetic diversity of urban D. melanogaster populations, and the factors that influence their distribution. We established a Citizen Science project, Vienna City Fly, which allowed us to concuct this research on Viennese populations of D. melanogaster. We also performed further analyses on D. melanogaster populations that were densely sampled through time and space by DrosEU, our partner consortium.
We are developing tools that facilitate extracting information for sample coordinates from gridded datasets to identify links between genetic variation along the whole Drosophila melanogaster genome and environmental variation. This approach will allow to identify genes that are putatively under selection and involved in adaptation to environmental change. Using machine learning approaches, we further aim to identify combinations of environmental factors that may influence the genetic diversity in natural populations which will help us to better understand the impact of climate change on the accelerating biodiversity crisis.
Research Questions#
Research Questions On Urban Drosophila
- What is the species composition of Drosophila communities in urban environments?
- What are the key environmental factors that determine the distribution of flies in the City of Vienna?
- How does the genetic diversity of urban D. melanogaster populations compare with that of populations from rural regions?
- Can citizen science provide reliable data on the diversity and ecology of Drosophila in urban environments?
- How does participation in such a project influence public awareness and interest in biodiversity and scientific research?
Research Questions On European Drosophila
- How does environmental variation across space and time correlate with patterns of genetic diversity in D. melanogaster populations?
- Which genomic regions or genes in D. melanogaster show signatures of adaptation to specific environmental conditions?
- Can combinations of environmental factors predict changes in genetic structure or the presence of adaptive alleles in natural populations?
Workflow#
In our Citizen Science project called Vienna City Fly we collected over 19'000 new specimen of Drosophilid flies. 47 Populations were sequecend on a whole genome scale and genomic information was analysed together with environmental data for the city of Vienna. The workflow integrates earth observation data with Drosophila records through preprocessing, standardization, and variable selection. We then conduct descriptive and biodiversity analyses, including diversity indices, ordinations, and mixed-effects models. Rarefaction, redundancy analysis, and species distribution modeling further assess sampling completeness, environmental drivers, and habitat suitability. The full workflow to conduct research on urban Drosophila can be found in the GitHub Repository UrbanDrosophilaEcology.
We also work with genomic data from Drosophila melanogaster at population level, available at DEST.bio.
Environmental data is available from various sources, matching our regions and times of interest. We used FAIRiCUBE infrastructure to access earth observation and environemntal data to match our sample coordinates. We also developed a tool called QueryCube to access and download data for point coordinates.
We combine both data types (genomic and environmental) by doing redundancy analysis. The complete workflow including code and instructions can be found in the GitHub Repository of UseCase3.
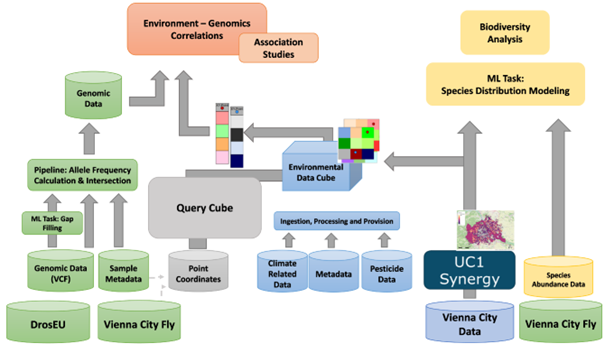
Data and ingestion#
Use Case 3 mostly uses APIs available via the FAIRiCUBE infrastructure. One data source, that was ingested in the Rasdaman architecture was the Glocbal Pesticide Grid. For Vienna City Fly Analysis, we collaborated with UC1 to process and harmonize environmental data from the City of Vienna.
Processing steps and ML applications#
Environmental Data Filtering#
To ensure high-quality and interpretable analyses, the environmental dataset underwent a thorough filtering process. The following criteria were used to clean and retain only informative and reliable data points:
1) Filtering Out Missing Environmental Values
Any data points with missing values for one or more environmental variables were removed. Incomplete records can bias statistical models and reduce interpretability, so only complete cases were retained for analysis.
2) Exclusion of Monomorphic Environmental Variables
Environmental variables showing no variation (i.e., constant across all samples) were discarded. Such variables do not contribute to explaining genetic variation and can interfere with statistical modeling.
Genomic Data Filtering#
1) Removal of Records with Missing Coordinates
Sample entries lacking geographic coordinates (latitude and/or longitude) were excluded, as spatial location is essential for linking environmental variables with genetic data. These records cannot be reliably used in spatial or genotype-environment association analyses.
2) Removal of Records with Missing Time Information
Observations without a valid timestamp (e.g., year, season, or date) were filtered out. Temporal information is critical for aligning genetic sampling with environmental conditions and for detecting temporal trends.
3) Converting VCF File to Allele Frequency File
Raw variant data in VCF (Variant Call Format) is processed to extract allele frequency information per population or individual. This step transforms the VCF into a tabular format suitable for downstream statistical analysis.
4) Annotating SNPs
Single Nucleotide Polymorphisms (SNPs) are annotated using reference databases to determine their genomic context (e.g., intergenic, intronic, exonic) and potential functional impacts. This aids interpretation and prioritization of variants.
ML-Application: Imuptation of Missing Genomic Data#
In genomic data, missing values frequently arise due to various technical or experimental limitations, and they are often unavoidable. To ensure accurate analysis, one common approach is to remove data entries with missing values entirely. However, this method can significantly reduce the dataset size, leading to a loss of valuable statistical power and critical information. As a result, the imputation—or estimation—of missing data becomes a crucial step in preserving the integrity of the dataset. To address this challenge, project partners at NILU have developed a machine learning algorithm specifically designed to accurately estimate and fill in these missing values, thereby enabling more comprehensive and reliable genomic analyses.
GitHub GapFilling
Solution(s)#
Performing RDA (Redundancy Analysis)#
RDA is a multivariate statistical method that examines how much of the genetic variation can be explained by environmental predictors. We chose RDA over unconstrained methods like PCA because we were specifically interested in explaining speciesvariation using external variables, rather than exploring the data structure without context. It provides a robust framework to link ecological patterns to environmental drivers, helping us interpretcomplex multivariate data in a meaningful, hypothesis-driven way and is particularly useful for identifying patterns of local adaptation and visualizing genotype-environment relationships.
Accquiring Point Coordinates For Environmental Data#
Offering access to just the point coordinates from large spatial datasets can significantly enhance the efficiency of data workflows and lower the barrier to spatial analysis. By allowing simple extraction information — like observation sites or sampling locations— without the handling full raster datasets, QueryCube simplifies analysis and reduces both storage and computational demands.
Resources#
Environmental Data#
We used FAIRiCUBE infrastructure to access earth observation and environmental data from the following sources:
- Rasdaman Web Service Cataloge
- Austrian Open Data: Public Data Vienna
Genomic Data#
Programs and Software#
All Programs and Software that we used for our Use Case can be found in our Use Case 3 specific GitHub repository.
Partners#
Naturhistorisches Museum Wien, Natural History Museum Vienna (NHMW)